OpenClaw en local avec Ollama - Rock Robot
J’ai dû rédiger un CV pour un client potentiel ; c'était l’occasion de tester OpenClaw en local.
Je voulais profiter de l’occasion pour tester des modèles plus puissants sur ma carte graphique Nvidia RTX 2070, avec 8 Go de RAM.
À l'époque (oui oui, l'année dernière), elle faisait tourner vaillamment Llama 3.1 et Qwen3 en 8B. Quand on a besoin de faire un résumé, de rédiger un document ou de faire tourner un chat, il suffit d'un petit contexte de 4K qui tient facilement dans 8 Go de RAM. Mais ça, c'était avant le vibe coding
Est-ce qu'on peut faire tourner les agents OpenCode ou OpenClaw avec un LLM en local ?
Configuration de base d'Ollama avec Qwen3.5:2b
Je ne vous fais pas l'affront de faire un tuto sur l'installation d'Openclaw et d'Ollama. Il y en a plein sur Internet, donc je pars du principe que vous y êtes arrivés sans souci. Par contre je vais vous montrer ce que j'ai dû corriger.
Contrairement à OpenCode, OpenClaw sait régler la taille du contexte des modèles sur Ollama.
D'ailleurs, il se moque pas mal de la taille de contexte par défaut d'Ollama
(ce que je vous ai montré dans l'article précédent).
On le voit à la taille du contexte affichée par ollama ps une fois qu’on lui pose une question :
c’est la taille maximale du modèle.
Si vous voulez éviter de consommer toute la RAM de votre carte graphique,
éditez votre fichier ~/.openclaw/openclaw.json et modifiez la valeur de contextWindow de votre modèle:
{
"models": {
"providers": {
"ollama": {
"models": [
{
"name": "qwen3.5:2b",
"contextWindow": 65536,
}
]
}
}
}
}
Ici j'ai demandé un contexte de 65536 tokens.
Donc pour commencer, j'ai utilisé Qwen3.5 en 2b avec 64K tokens. Ça tenait en mémoire sans trop de problèmes, c'était rapide.
Honnêtement, ce modèle n'est pas bon. Il fait des fautes de français et n'est pas très pertinent mais surtout il part facilement en cacahuète :
- Il boucle sur lui-même régulièrement ;
- Quand il lance des commandes qui échouent, il n'arrive pas vraiment à corriger les problèmes.
J'ai donc essayé d'utiliser un meilleur modèle.
Tests avec Qwen3.5:4b
À l’époque, j’utilisais un modèle Qwen3 en 8b sans trop de problèmes, mais avec de grands contextes, ce n’est pas la peine d’y penser. Mais est-ce que Qwen 3.5 est vraiment meilleur que Qwen 3 ? Et est-ce que les améliorations permettent à un modèle 4B d’être aussi performant que le modèle 8B de la génération précédente ?
Cet article
présente un graphique indiquant les performances en fonction des cas d'utilisation et des poids/génération des modèles :
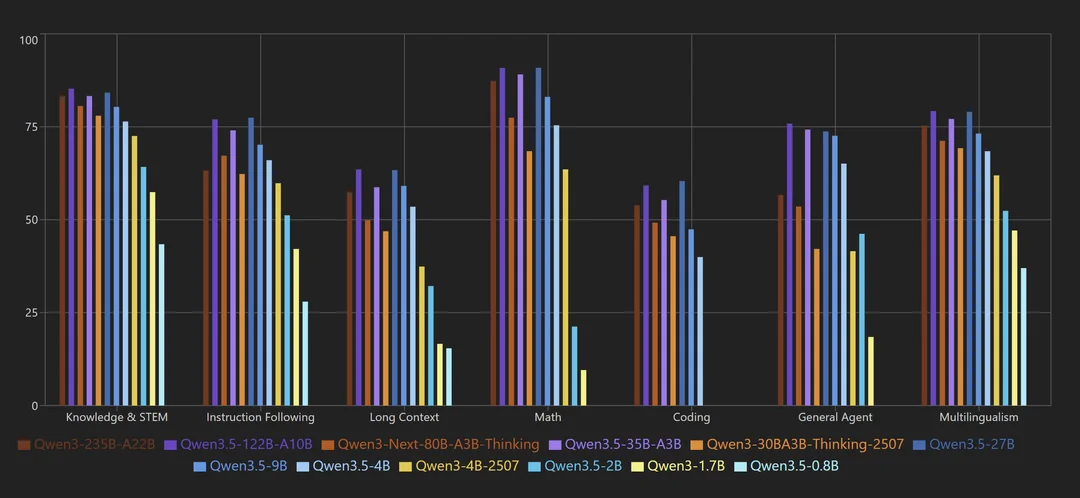
Il ne parle pas de Qwen3:8b mais on peut voir deux choses sur le graphique :
- Pour un agent, le modèle 4B est 30% plus performant que le 2B ;
- Ce n'est pas trop la peine d'utiliser un grand contexte avec le 2B.
Donc j'ai essayé le modèle 4B en passant le contexte à 32K tokens.
Ça tient en VRAM, c'est rapide, mais dès qu'il lance une commande qui plante et affiche un log d’erreur... le contexte déborde. Si j'ai de la chance, la compression du contexte se lance automatiquement, sinon on est bon pour recommencer la session. Ça devient rapidement inutilisable.
Et là je me souviens que quelqu'un m'a parlé de TurboQuant 4 de Google qui compresse le KV Cache, donc normalement on pourrait utiliser un contexte de 64K dans 8Go de RAM
Compression du KV Cache
Le KV Cache est une technologie qui réduit considérablement (de 5 à 10 fois) le temps de traitement, mais cela se fait souvent au détriment de la consommation de mémoire.
En fouinant dans les logs d'Ollama, on voit la décomposition de l'utilisation de la RAM par Ollama :
msg="offloading 32 repeating layers to GPU"
msg="offloading output layer to CPU"
msg="offloaded 32/33 layers to GPU"
msg="model weights" device=CUDA0 size="2.0 GiB"
msg=msg="model weights" device=CPU size="1.6 GiB"
msg="kv cache" device=CUDA0 size="1.8 GiB"
msg="compute graph" device=CUDA0 size="1.0 GiB"
msg="compute graph" device=CPU size="126.6 MiB"
msg="total memory" size="6.6 GiB"
Ollama décompose ses besoins en RAM :
- Les poids (model weights) : le modèle en lui-même ;
- Le fameux KV Cache ;
- Le graphe de calculs (compute graph) : stocke les résultats intermédiaires et permet de faire des optimisations de calculs.
Donc le KV Cache consomme pas mal de RAM et ça empire quand on augmente la taille du contexte.
Donc j'ai cherché si Ollama (et surtout llama.cpp, qui fait l'inférence) pouvait utiliser TurboQuant 4 de Google. Il y a un projet "Atomic llama.cpp", un fork de llama.cpp qui implémente l'algorithme, mais ce n’est pas utilisé par Ollama.
Par contre, dans cette discussion sur le projet GitHub de llama.cpp,
certains intervenants trouvent que ce n'est pas si intéressant par rapport aux algorithmes de compression déjà implémentés dans llama.cpp.
Donc, il existe déjà la possibilité de quantifier le KV Cache en 8 bits (q8_0) pratiquement sans perdre en pertinence.
On peut aussi quantifier en 4 bits (q4_0), mais les pertes sont plus marquées ;
en effet, les petits modèles seraient plus impactés que les grands.
Ok donc on peut déjà utiliser la quantification du KV Cache (même si elle ne sera pas aussi efficace que TurboQuant) mais qu’est-ce que ça représente réellement ? Et bien, pour vous faire une idée, il y a pas mal de simulateurs de consommation de VRAM sur Internet. Personnellement, je vous conseille celui-ci qui semble assez clair et complet.
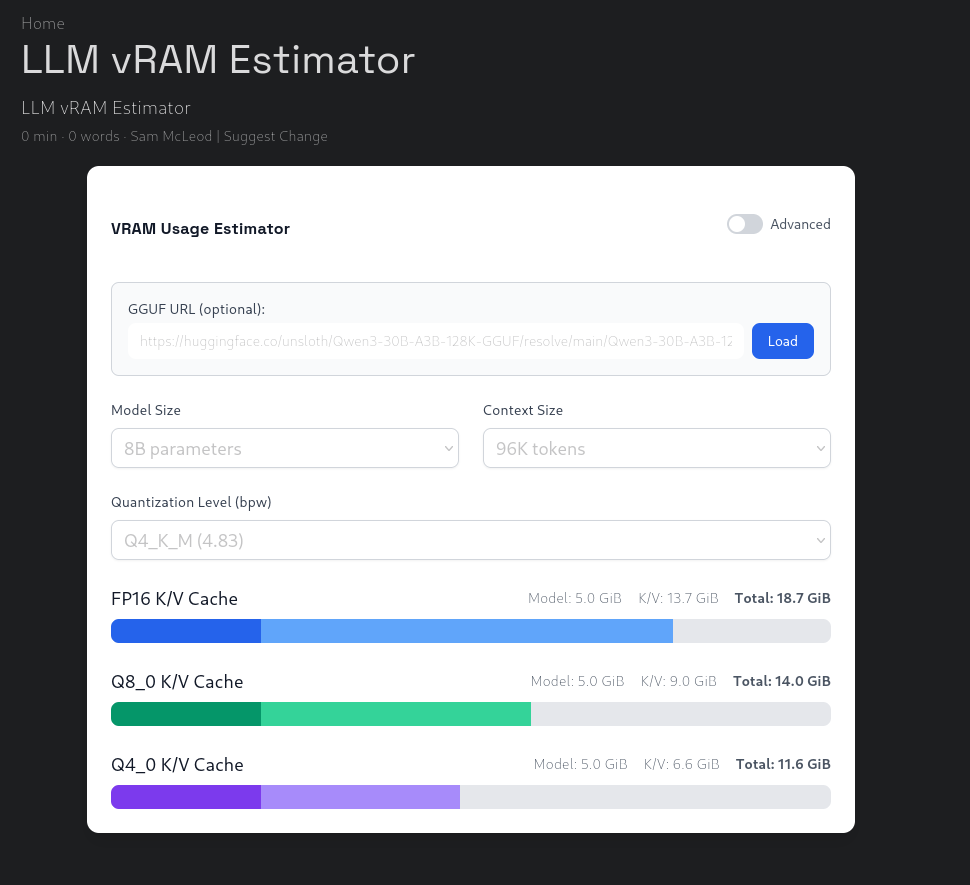
En haut, vous pouvez mettre l’URL du modèle sur Hugging Face, mais vous pouvez, à la place, renseigner la taille du modèle, la quantification du modèle et la taille du contexte qui vous intéresse.
Dans les graphiques du dessous, vous avez une ligne par quantification du KV Cache et sur cette ligne :
- À droite, la RAM consommée par le modèle, le KV Cache et le total ;
- En couleur foncée : la consommation des poids du modèle (vous voyez que le foncé est identique sur les 3 lignes) ;
- En couleur claire : la consommation du KV Cache quantifié (vous voyez que les barres diminuent en fonction de la quantification).
J'utilise le q8_0, déjà que les petits modèles ne sont pas super pertinents, on va éviter la quantification q4_0.
Et avec le q8_0 j'ai déjà pu doubler la quantité de contexte.
Mais comment on fait dans Ollama ? C'est indiqué dans la doc.
Il suffit d'utiliser la variable d'environnement suivante quand on lance ollama server :
OLLAMA_KV_CACHE_TYPE=q8_0
Finalement, j'ai rapidement atteint la limite de 8 Go de RAM pour utiliser les 64K de tokens : j’ai quand même dû éteindre Firefox.
OpenClaw et Reaction Resume
Une fois que mon OpenClaw avait suffisamment de contexte, j’ai créé ma base de connaissances. Ensuite je voulais qu’OpenClaw fasse la mise en page de mon CV tout seul.
Pour ça, j’ai trouvé un programme open source : Reactive Resume, également accessible en ligne sur le site https://rxresu.me. C'est un site qui permet de créer son CV section par section, d'utiliser des templates de CV et de faire un peu de mise en page. Il a un serveur MCP intégré et aussi un skill disponible pour les agents.
Alors je ne sais pas si OpenClaw a du mal avec le MCP,
mais il n'arrivait pas à utiliser le serveur MCP quand je lui indiquais dans son fichier de configuration,
ni quand j'ai installé le skill mcporter.
J'ai lu quelque part que les agents préfèrent les skills aux serveurs MCP, donc j'ai installé le skill resume-builder
(écrit par l'équipe de Reactive Resume et, oui, je l'ai lu avant de l'installer).
L'approche du skill est intéressante ;
elle recommande à OpenClaw de créer un JSON selon un format disponible sur Internet et de faire une requête HTTP pour l'envoyer à Reactive Resume.
Cependant, de mémoire, les petits modèles ont du mal à générer un JSON qui respecte scrupuleusement un standard.
Je suis un peu sceptique.
Mais à partir de là, OpenClaw n'arrivait même plus à lire un fichier ;
j’ai peut-être fait une erreur dans la configuration.
Le LLM n'arrivait plus à appeler ses tools,
pourtant, ils apparaissent dans l'interface textuelle en lançant /tools.
Donc je ne suis pas sûr que l'interface soit fiable.
Ça démontre un manque de rigueur dans la conception de l'outil.
J’ai beaucoup appris sur OpenClaw, et je pense qu’un simple utilisateur ne pourrait pas s’en sortir. Et je suis super emballé par le principe de déléguer des tâches à un agent. Mais pour un logiciel qui a pas mal fait la hype ces derniers mois, je trouve que ce soft marche très mal. La doc est très technique, mais elle manque cruellement d’explications de base sur le fonctionnement global.
Pour être honnête, j'ai craqué et fait le CV à la main sur l'appli.
Conclusion
Avec du temps et de la patience, on peut utiliser une carte graphique avec seulement 8 Go de RAM avec des agents IA, pour peu qu’on accepte de faire des compromis.
En l’état, je ne peux pas recommander OpenClaw : soit il a des permissions trop larges et pourrait poser problème, soit ses protections sont si strictes qu’il devient inutilisable. La doc est obscure. Peut-être que j'étais dans un cas particulier, mais je n'ai pas l'impression d'être le seul à galérer.
L'expérience avec OpenCode était bien plus agréable.
J’ai commandé une carte AMD 9060 XT avec 16 Go de RAM. Et oui, j’ai envie de tester ce que fait la concurrence même si c’est pas très hype. Et Ollama a intégré un nouvel agent, Hermes. Je vous en dis plus la semaine prochaine.